Context:
As our traffic scaled, we noticed that our postgres database quickly became our bottleneck, with slow & resource intensive sql queries. In response to this, we allocated engineering resources to address the database bottlenecks and increase the observability of our postgres instance. The result of this is a faster user experience, and a grafana dashboard that gave us health information for our databse, including cpu usage, mem usage, pg bouncer connections, etc. Notably, one of the panes in the grafana dashboard showed us the size of each table.
Discovery
After the dashboard was up, we noticed that since around 11/01 7am PST, the size for one of our tables started increasing with at a much higher rate.
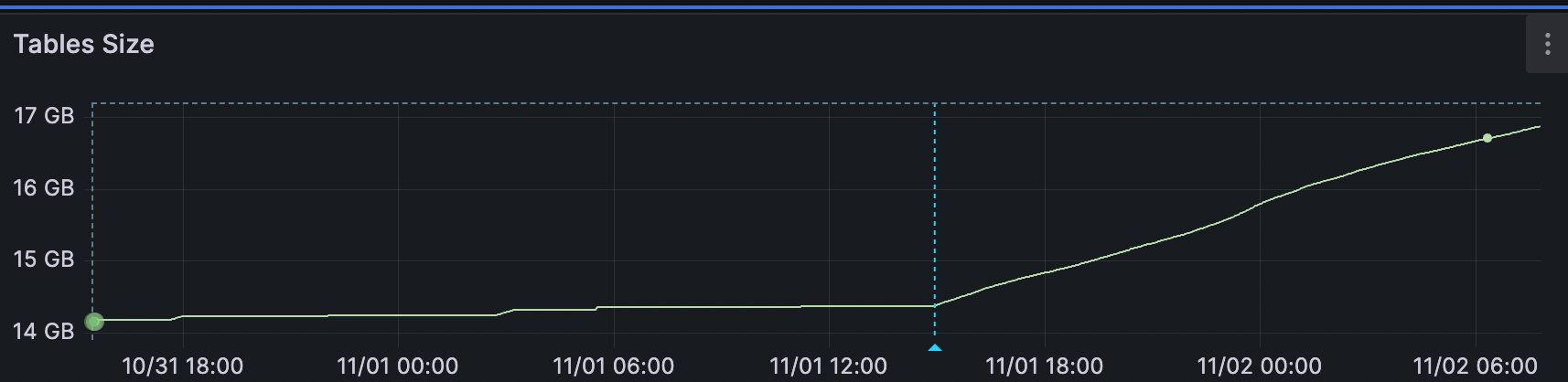
Some things to note:
- This table has a jsonb column
- We have just added an index to it the night before, shown by the small stepwise increase in table size.
This is obviously not normal and highly suspicious, our immediate thoughts on this were 3 fold.
- This is a data source error
- This is an application error from our code
- This is from a bad actor
Addressing the data source error, we ran the following query to verify that the table size data in grafana is actually correct.
WITH sizes AS (SELECT pg_total_relation_size('public."Conversation"') AS total_size_bytes,
pg_relation_size('public."Conversation"') AS data_size_bytes,
pg_indexes_size('public."Conversation"') AS index_size_bytes)
SELECT pg_size_pretty(total_size_bytes) AS total_size,
pg_size_pretty(data_size_bytes) AS data_size,
pg_size_pretty(index_size_bytes) AS index_size,
pg_size_pretty(total_size_bytes - data_size_bytes - index_size_bytes) AS toast_and_others_size,
pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), '0/0')) AS wal_size
FROM sizes;
PostgreSQL’s TOAST (The Oversized-Attribute Storage Technique) mentioned here is a system that automatically stores large table fields (like strings or binary data) in a separate area to keep the main table size small and access performance high. When the json data cannot be fit into a single page of 8kb, it will be stored with TOAST.
To address the application code and bad actor suspicion, we ran an array of SQL queries that analyzed the number of entries and the sum of the jsonb columns over time to see if there were any anomalies that stood out, but we couldn’t find anything. The number of entries created and updated followed a normal trend, and the size of the jsonb columns also look normal. The time that the increase started also did not match any code deployments that we had.
Digging Deeper
To do further resource intensive queries and not affect production, we took our hourly backup and restored it in our staging database. After running the same query above on the staging database, we got the following results:

Notice that the datasize and index size are close to each other, but there is a huge disparity in toast sizes. This caught our attention.
Based on our understanding of postgres, we first suspected that it was due to difference in data freshness and how the toast data is compressed since the staging data is restored in one go, but we weren’t able to find any documentation to support this claim.
Doing some more research, we noted that the query pattern of this table had frequent updates on the jsonb column. From the huge difference in toast size, we suspected that there could be data that has not been garbage collected.
According to Postgres MVCC, updates are handled by creating a new version of a row and marking the old version as obsolete, resulting in a dead tuple. The large disparity of the size of the same table in production and can potentially be explained by frequent updates in production and data that has not been garbage collected.
To clean up the dead tuples we ran the VACUUM command. The vacuum command, unlike the VACUUM FULL command, does not allow the system to reclaim disk space, but only frees up space for the same table to use. However, it does not lock up the entire table, which VACUUM FULL does.
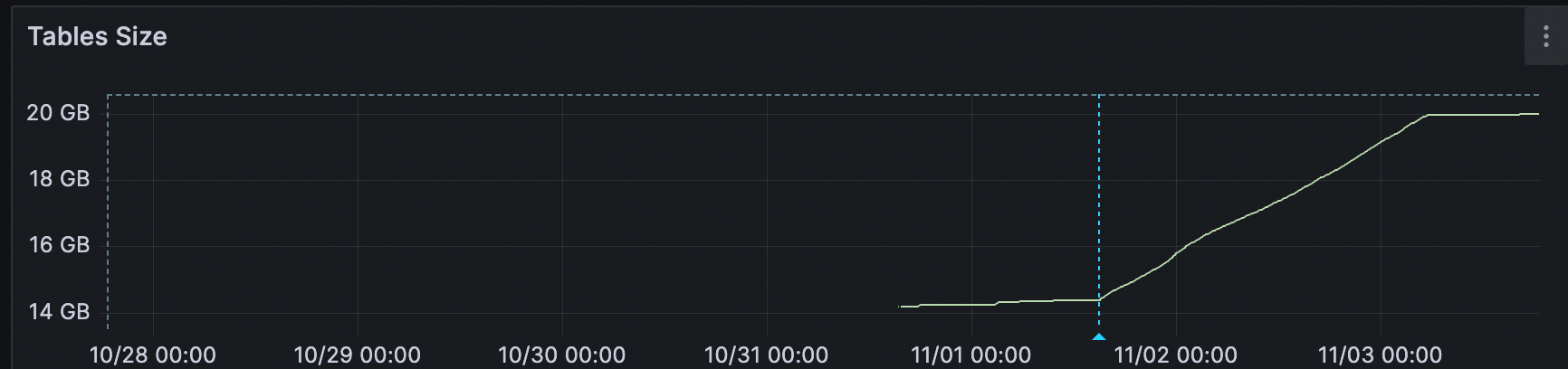
Just like we thought, the space did not decrease, but instead became level, as the stale data is garbage collected and space freed up for new data to fill in. This might not be the ultimate solution to this issue, but at the very least alleviated the pressure of our rapidly growing table size.
The solution of collecting dead data seems very obvious in hindsight, but this experience provided us a great opportunity to learn how to debug a Postgres issue, increase the awareness for regular monitoring and maintenance on the database, and learn a little bit more about what’s going on under the hood.
Related articles worth reading found afterwards during the writing of this post: https://stackoverflow.com/questions/49660810/postgresql-vacuuming-a-frequently-updating-jsonb-field
Q: Why didn’t this happen before?
Maybe a code change caused a significant increase in of updates. Or we had a user / bad actor that spammed our update endpoint that caused a large number of updates.